Index is a must
User Rating:  / 1
/ 1
- Details
-
Category: Development
-
Published on Monday, 24 January 2011 19:08
-
Written by Ove
-
Hits: 3771
Jeg lærer stadig noe nytt angående databaser og nå ser jeg virkelig nytten av indekser. En index brukes for å få en raskere behandling av en forespørsel til databasen. La oss tenke oss en rekke med tall som ikke er sortert og som kan forekomme i en hvilken som helst rekkefølge. For å finne et bestemt tall i denne rekken uten å bruke index må databasemotoren søke gjennom alle tallene eller til den kommer til ønsket tall. Dette kan ta tid hvis tabellen har 100 millioner tall. Derfor får man en vesentlig forbedring hvis man oppretter en index for disse tallene. (eller tekstene eller hva det måtte være). Da vil databasemotoren lage en tabell der tallene er sortert og med henvisning til hvor dette tallet finnes i den orginale tabellen. Teknikken som brukes for sortering og oppdatering av denne indexen som blir gjort automatisk av databasemotoren bygger etter hva jeg forstår på binære søketrær. Dette er en utrolig fin teknikk for sortering. Jeg har ikke brukt index på ID til foreldre i AgetoAgeSqlite og derfor fikk jeg ikke så rask responstid som ønskelig i for eksempel "Close relations" (Group View). Derfor har jeg nå lagd et vindu der man kan klikke "Create father, mother index" og en knapp for å fjerne denne indexen om man skulle ha lyst til det. Da jeg testet dette fikk jeg hakeslepp og håret reiste seg flere meter over hodet. Jeg testet med en database med ca 150 000 personer og det var omtrent ikke noe ventetid for å få listet opp etterkommere av en person med 4500 etterkommere. "Close relations" jobber som et lyn når man lager index for ID til foreldre. Det artige er at i prinsippet kan man lage og slette indexer som man vil og indexene vil oppdateres automatisk av databasemotoren. Jeg kunne ha lagd det slik at disse indexene ble lagd automatisk når man oppretter en ny database, men fordelen med å la brukeren lage indexene er at brukeren også da kan slette indexen om dette skulle være ønskelig (f.eks hvis man vil importere 500 000 personer fra en GED fil kan det være noen sekunder å spare ved å slette indexen først. Så kan man bare lage indexen på nytt etter at importen er ferdig) Det er mulig jeg kommer til å lage et vindu er brukeren vil ha full kontroll over hvilke tabeller og felter som man vil ha index på. Brukeren kan da f.eks lage index over Firstname og Lastname osv. og få en superrask behandling av søk på disse. Som nevnt, indexer medfører litt ekstra arbeid for databasemotoren når man oppdaterer data og importerer data så ikke lag indexer i hytt og pine men indexen for ID til foreldre var virkelig nyttig. Men nå som et første skritt er altså muligheten for å indexere ID til foreldre til stede og oppdateringen er lastet opp. GOD FORNØYELSE!
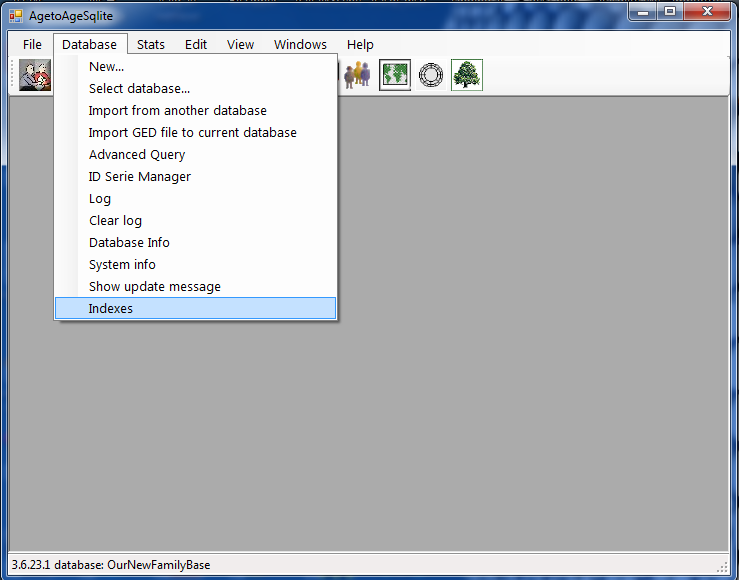
Ved å velge Indexes kommer man til dette vinduet hvor alle indexer vises. Alle tabeller i AgetoAgeSqlite har en index (noen tabeller har to felter som tilsammen blir én index, f.eks ata_marriages har to felter ID1 og ID2 som er id til de som har giftet seg og tilsammen blir de en unique index). Men brukeren kan altså opprette flere indexer for felter som ikke har noen index. Som nevnt er ikke FatherID og MotherID i persontabellen indexert som standard. Dette er verdier som ikke er unique i tabellen, så man må ikke lage en unique index for disse, mange personer kan ha samme far og mor men resultatet av å lage en IKKE UNIQUE INDEX hadde altså en enorm virkning på hastigheten for å finne personer med en bestemt far eller mor.

Noen vil kanskje tenke nå at nei, huff dette blir for avansert for meg... men fortvil ikke, det vil komme noen knapper man bare klikker for å lage en index man ønsker å ha. (og en knapp for å slette den om den ikke er så interessant lenger). Det morsomme er at programmet ikke trenger å modifiseres for å bruke en index, databasemotoren vil selv velge om den kan bruke index eller ikke når den får en forespørsel. Hvis brukeren har opprettet en index for feltet man søker i så vil databasemotoren automatisk bruke denne hvis spørringen er slik at index kan brukes for å finne resultatet. Disse indexene som brukeren lager vil ikke endre noenting på strukturen i tabellen som indexen berører. Tabellen vil være akkurat som før man laget indexen, det er databasemotoren som håndterer dette, la oss ta et eksempel brukeren lager index på Firstname i persontabellen, databasemotoren vil da lage en egen tabell (helt på egenhånd) og kopiere alle fornavn fra persontabellen til denne nye tabellen med et felt som viser hvor i persontabellen den finner dette navnet. Tabellen vil være sortert på fornavn med binert søketre teknikk. Derfor er det helt trygt å lage og slette indexer så mye man vil. Hvis brukeren endrer noen data i persontabellen som berører indexen vil indexen automatisk bli oppdatert i den nye tabellen. For dem som er interessert kan jeg vise hvordan jeg får databasemotoren til å lage en slik index. Kommandoen jeg sender til databasemotoren for å lage index på firstname er:
"CREATE INDEX firstnameIndex ON ata_persons (firstname)"
for å slette den er det så enkelt som:
"DROP INDEX firstnameindex"
Dette gjelder for SQLIte, for andre systemer kan syntaksen være litt annerledes. Men dette er bare et eksempel på å lage index, i de fleste tilfeller går søket så fort uten bruk av index for firstname at det har ingen hensikt å lage index for firstname. Om det tar 1/4 dels sekund eller 1/1000 dels sekund er vel ikke så viktig når man søker på navn. Det avhenger egentlig av hvor mange forskjellige navn man har i databasen. Har man mindre enn 500 000 forskjellige fornavn i databasen er det kanskje ingen vits å bruke index på bare fornavnet. Men man kan slå sammen flere felter til en index, f.eks "CREATE INDEX nameIndex ON ata_persons (firstname, lastname)".
Konklusjonen er at indexer er et must når programmet gjentar en rekke forespørsler til databasen der man spør på et felt som ikke ble indexert da tabellen ble laget. "Close Relations" er et godt eksempel på hvor viktig det er å bruke index på father- og motherID. Man har en masse forespørsler der på father og motherID. Også "Descendant Tree" jobber 100 ganger raskere med indexert father- og motherID. Jeg er nesten kommet til den endelige konklusjon at disse feltene skulle vært indexert når brukeren lager en ny database. Jeg kan ganske enkelt bare legge til kommandoen CREATE INDEX fathermotherID ON ata_persons (fatherID, motherID) når brukeren lager en ny database eller jeg har alternativet å definere feltet father- og motheriD som indexert når tabellen ata_persons blir laget. Eller det tredje alternativet å la brukeren selv lage den ved å klikke en knapp. Ved det siste alternativet kan brukeren slette denne indexen og lage den på nytt når behovet oppstår. Hva er best? Noen som har noen tanker om dette?
27.01.2011 - Jeg tror jeg satser på å la programmet utføre CREATE INDEX fathermotherID ON ata_persons (fatherID, motherID) når man lager ny database. Father og motherID peker til PID i den samme tabell så jeg kan ikke bruke en relasjon her (bruk av primary og foreign keys). Indexen vil oppdateres av databasemotoren etterhvert som man legger til personer. Jeg har nå funnet en masse GED filer som jeg har importert og har litt mer enn 200 000 personer i databasen. Artig å se hvor mange som heter det og det og man kan lage statestikk over forskjellige ting med et godt utvalg av tilfeldige personer.
Har også flyttet "Indexes" til "Database Info" vinduet der det også er en ny knapp "Table Structure" der man kan vise tekniske detaljer for hvert felt i alle tabellene som brukes. Oppdateringen er lastet opp.
28.01.2011 - Lastet opp ny oppdatering av AgetoAgeSqlite som lagrer verdi på "Checked" på personskjemaet. Det er nyttig å kunne merke en person for å finne den hurtig igjen senere. Bare å skrive i SQL feltet i personlisten "where Marked = '1'", samtidig har jeg laget funksjon som gjør at man kan dobbelklikke gjeldende Page nummer i personlisten for å skrive inn nummer på siden man vil gå til.
For å finne GED filer for å teste importen i AgetoAgeSqlite har dette stedet en masse filer http://www.genealogyforum.com/gedcom/